OpenAI ရဲ့ GPT-5 ဟာ developer များအတွက် coding နဲ့ agentic tasks အပေါ်မှာ အကောင်းဆုံး စွမ်းဆောင်ရည်ကို ပြသထားတဲ့ နောက်ဆုံးထွက် model အသစ်ဖြစ်ပါတယ်။ SWE-bench Verified ပေါ်မှာ 74.9% နဲ့ Aider Polyglot ပေါ်မှာ 88% ရရှိထားပြီး၊ bug ပြုပြင်ခြင်း၊ code edits လုပ်ခြင်း၊ စုံလင်တဲ့ codebase Q&A များအတွက် ထူးချွန်စွာ လုပ်ဆောင်နိုင်ပါတယ်။ Front-end web development ထဲမှာပါ o3 ကို 70% အထိ ကျော်လွန်နိုင်ခဲ့ပြီး၊ အတိအကျ လမ်းညွှန်ချက်များကို လိုက်နာနိုင်တဲ့ ပူးပေါင်းဆောင်ရွက်ဖော်အဖြစ် ဒီဇိုင်းထုတ်ထားပါတယ်။ Tool call များအကြား တိကျတဲ့အကြောင်းပြချက်များကို ရှင်းပြပေးနိုင်ပြီး၊ ကြာရှည်တဲ့ workflow များကို ထိရောက်စွာ ကိုင်တွယ်ပေးနိုင်ပါတယ်။

GPT-5 For Developers
Early adopters များက GPT-5 ကို "the smartest model" လို့ ခေါ်ကြပြီး၊ tool-calling တိကျမှု၊ နက်ရှိုင်းတဲ့ reasoning နဲ့ အလွန်မြန်ဆန်တဲ့တုံ့ပြန်မှုကို အထူးသဖြင့် low-reasoning mode ထဲမှာပဲ အထူးသဖြင့် ချီးကျူးကြပါတယ်။ τ2-bench telecom ပေါ်မှာ 96.7% ရရှိထားပြီး၊ စဉ်ဆက်မပြတ် သို့မဟုတ် တပြိုင်နက် လုပ်ဆောင်ရတဲ့ tool call များကို လမ်းပျောက်မသွားဘဲ ထိန်းသိမ်းနိုင်ပါတယ်။ Error handling နဲ့ long-context retrieval ထဲမှာလည်း ထူးချွန်ပါတယ်။
API ထဲမှာ အသစ်ထည့်သွင်းထားတဲ့ developer controls တွေမှာ –
- Verbosity (low, medium, high) ဖြင့် တုံ့ပြန်စာသားအလျား ထိန်းချုပ်နိုင်ခြင်း
- Reasoning_effort ထဲမှာ minimal setting ထည့်သွင်းထားပြီး မြန်ဆန်တဲ့အဖြေ ပေးနိုင်ခြင်း
- Custom tools တွေကို plaintext calls နဲ့ grammar constraints ဖြင့် အသုံးချနိုင်ခြင်း
GPT-5 ကို gpt-5, gpt-5-mini, gpt-5-nano စတဲ့ မော်ဒယ်ပေါင်း မျိုးစုံနဲ့ ရနိုင်ပြီး performance-cost-latency အချိုးကျ စွမ်းဆောင်နိုင်ပါတယ်။ API version မှာ reasoning model အပြည့်အဝကို အသုံးပြုပြီး performance အမြင့်ဆုံး အဆင့်ဖြင့် အဆင်ပြေအောင် တိကျစွာ ချိန်ညှိ ပေးနိုင်ပါတယ်။
Coding
GPT-5 က coding အတွက် o3 ကို အများကြီး ကျော်လွန်နိုင်ပါတယ်။ SWE-bench Verified ပေါ်မှာ 74.9% ရရှိထားပြီး (22% token သက်သာခြင်း၊ 45% tool call သက်သာခြင်း)၊ Aider Polyglot ပေါ်မှာလည်း 88% တိုင်းတာချက်နဲ့ record အသစ်တင်နိုင်ခဲ့ပါတယ်။ အမှားအယွင်းများကို သုံးပုံတစ်ပုံလျော့ချပေးနိုင်ပြီး၊ စုံလင်ပြီး စွမ်းဆောင်ရည်ကြီးတဲ့ codebases များထဲကို လွယ်ကူစွာ ရှာဖွေရန်၊ တိုးတက်အောင်လုပ်ရန် ထိရောက်စွာ ကူညီပေးနိုင်ပါတယ်။
Frontend Engineering
Web app interfaces တည်ဆောက်ရာမှာ GPT-5 က ပိုမို သန့်ရှင်းတဲ့ code၊ စိတ်ကူးယဉ်တန်ဖိုးမြင့်တဲ့ UI တွေ၊ နည်းပညာပိုင်းဆိုင်ရာ သဟဇာတဖြစ်အောင် ထုတ်ပေးနိုင်ပါတယ်။ o3 နဲ့ နှိုင်းယှဉ်သုံးသပ်မှုတွင် developer 70% က GPT-5 ကို ပိုမိုကြိုက်နှစ်သက်ကြပါတယ်။
ဒီထဲမှာ GPT-5 တစ်ချိန်ထဲမှာ Prompt တစ်ခုနဲ့ ဘာတွေ လုပ်နိုင်မလဲ ဆိုတာကို စိတ်ဝင်စားဖွယ် အနည်းငယ်ရွေးချယ်ပြီး မျှဝေထားပါတယ်။
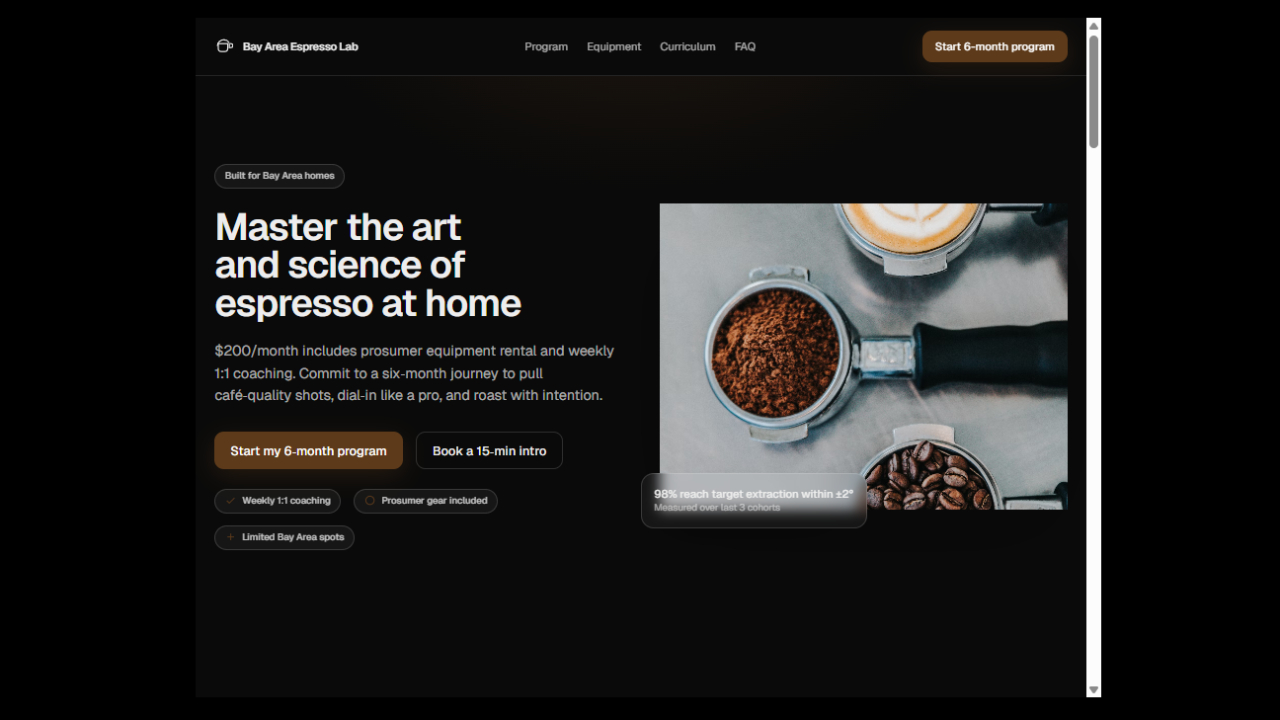
Espresso Lab website
Prompt: Please generate a beautiful, realistic landing page for a service that provides the ultimate coffee enthusiast a $200/month subscription that provides equipment rental and coaching for coffee roasting and creating the ultimate espresso. The target audience is a bay area middle-aged person who might work in tech and is educated, has disposable income, and is passionate about the art and science of coffee. Optimize for conversion for a 6 month signup.
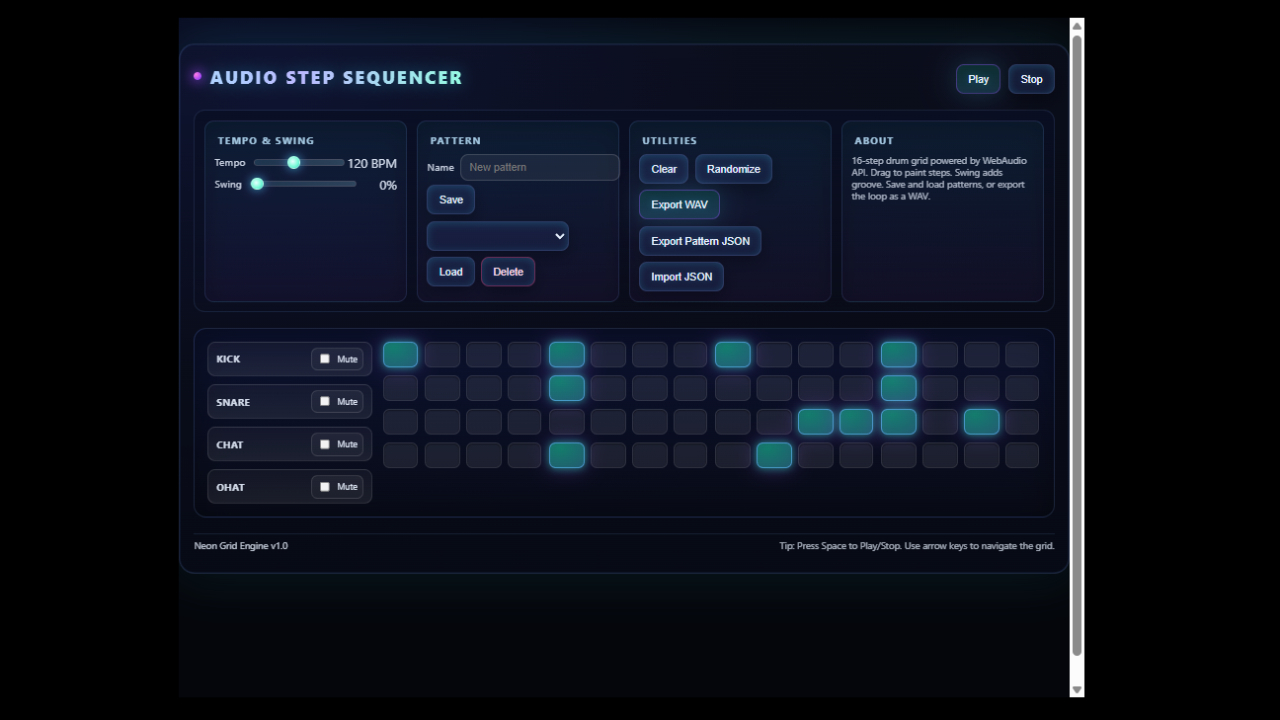
Audio step sequencer app
Prompt: Create a single-page app in a single HTML file with following requirements:
Name: Audio Step Sequencer
Stack: WebAudio API.
Goal: 16-step drum grid.
Features: Tempo, swing, patterns save/load, export WAV (render simple buffer).
The UI should be futuristic and make the play fun!
Outer space game
Prompt: Make a 2d space game, in which I can fly a ship, avoid and blow up asteroids, and dogfight with other computer-controlled AI. Be creative with the design of the ships. Ensure the gameplay works and is fun. Output code in a single next.js page.tsx file, which can be pasted directly into a next.js app created by create-next-app, alongside any context or instructions needed to run it.
အခြားသော ဥပမာ ပုံစံများကို GPT-5 Gallery မှာ ကြည့်ရှုနိုင်ပါတယ်။
Coding Collaboration
GPT-5 က အထူးသဖြင့် Cursor, Windsurf, GitHub Copilot, Codex CLI လို agentic coding tools တွေမှာ ပိုပြီး အားကောင်းတဲ့ ပူးပေါင်းဆောင်ရွက်ဖော် ဖြစ်လာပါတယ်။ Approval မစောင့်ဘဲ အဆင့်မြင့် အလုပ်များကို တက်ကြွစွာ ပြီးမြောက်အောင်လုပ်နိုင်ပြီး၊ tool call များအကြား အစီအစဉ်၊ အဆင့်အဆင့် update နဲ့ အကျဉ်းချုပ် အချက်အလက်များကို ပေးနိုင်ပါတယ်။
Agentic Tasks
Coding အပြင် GPT-5 သည် agentic tasks အမျိုးမျိုးမှာ ထူးချွန်စွာ လုပ်ဆောင်နိုင်ပါတယ်။ Instruction following (Scale MultiChallenge ပေါ်မှာ 69.6%) နဲ့ tool calling (τ2-bench telecom ပေါ်မှာ 96.7%) မှာ စံချိန်အသစ်များ တင်နိုင်ပါတယ်။ အဆင့်ဆင့် လုပ်ဆောင်မှုများကို စည်းလုံးသုံးသပ်ပြီး လက်တွေ့အသုံးချနိုင်တဲ့ အလုပ်များကို သေချာစွာ ပြီးမြောက်အောင်လုပ်ပေးနိုင်ပါတယ်။
Instruction Following
GPT-5 သည် ပိုပြီး ခက်ခဲ ရှုပ်ထွေးတဲ့ လမ်းညွှန်ချက်များကို လိုက်နာနိုင်စွမ်း အရင် model များထက် သာလွန်ပြီး ထိရောက်ပါတယ်။ COLLIE, Scale MultiChallenge, OpenAI internal evals ကဲ့သို့သော စမ်းသပ်မှုများမှာ အဆင့်မြင့် အမှတ်ရရှိထားပြီး၊ မလွယ်ကူတဲ့ အခက်အခဲများ၊ multi-turn conversations တွေကိုပါ တိကျစွာ ကိုင်တွယ်နိုင်ပါတယ်။
Tool Calling
GPT-5 ကို tool calling အတွက် တိုးတက်အောင် လေ့ကျင့်ထားပြီး၊ instructions ကို ပိုမိုတိကျစွာ လိုက်နာနိုင်ခြင်း၊ error များကို ကိုင်တွယ်နိုင်ခြင်း၊ အဆက်မပြတ် သို့မဟုတ် တပြိုင်နက် tool calls များကို လုပ်ဆောင်နိုင်ခြင်းတို့ ဖြစ်ပါတယ်။ ကြာရှည်တဲ့ tasks များမှာလည်း တိုးတက်မှုများကို အဆင့်လိုက် ဖော်ပြပေးနိုင်ပါတယ်။
ခက်ခဲဆုံး τ2-bench telecom စမ်းသပ်မှုမှာ အရင်မော်ဒယ် မည်သည့်မော်ဒယ်မှ 49% ကျော်မရနိုင်ခဲ့သော်လည်း GPT-5 သည် 97% အောင်မြင်ခဲ့ပါတယ်။ Long-context performance မှာလည်း o3 နဲ့ GPT-4.1 ထက် ပိုမိုထူးချွန်ပြီး၊ အထူးသဖြင့် input size ကြီးမားတဲ့ (256k tokens အထိ) အခါတွင် ထိရောက်စွာ အလုပ်လုပ်ပေးနိုင်ပါတယ်။
BrowseComp Long Context စမ်းသပ်မှုမှာလည်း GPT-5 သည် 89% အမှန်တကယ် မှန်ကန်မှုရရှိထားပြီး၊ တကယ့်သဘောကျန်မီ search result list များကို အခြေခံထားသော Q&A အတွက် သင့်တင့်ပါတယ်။
GPT-5 API မော်ဒယ်အားလုံး သည် 272,000 input tokens နဲ့ 128,000 output tokens ကို ထောက်ပံ့နိုင်ပြီး၊ စုစုပေါင်း context အနည်းဆုံး 400,000 tokens ထိ လက်ခံနိုင်ပါတယ်။
Factuality
GPT-5 သည် ပိုပြီး ယုံကြည်စိတ်ချရပြီး၊ o3 ထက် factual error များကို 80% လျော့ချနိုင်ပါတယ် (LongFact, FactScore စမ်းသပ်မှုများအပေါ်အခြေခံပြီး)။ ဒါကြောင့် accuracy အလွန်အရေးကြီးတဲ့ လုပ်ငန်းများ — coding, data handling, decision-making အတွက် အထူးသင့်တင့်ပါတယ်။
မော်ဒယ်ကို အရည်အချင်းအကန့်အသတ်များ အားကိုးနိုင်စွမ်း ပိုမိုတိုးတက်အောင် လေ့ကျင့်ထားပြီး၊ မမျှော်လင့်ထားတဲ့ input များကိုလည်း ထိရောက်စွာ ကိုင်တွယ်နိုင်ပါတယ်။ အထူးသဖြင့် health-related မေးခွန်းများမှာပါ တိကျမှန်ကန်မှု မြင့်တက်လာပါတယ်။ (သို့သော် အရေးကြီးတဲ့ output များကို အမြဲတမ်း စစ်ဆေးသင့်ပါသည်။)
New Features
- Minimal reasoning effort
Developer များသည် GPT-5 ၏ အတွေးအခေါ် အချိန်ကို reasoning_effort parameter ဖြင့် ထိန်းချုပ်နိုင်ပြီး၊ low, medium (default), high အပြင် minimal setting အသစ်ကို ထည့်သွင်းထားပါတယ်။ Minimal သည် အဖြေကို မြန်ဆန်စွာ ပေးနိုင်သော်လည်း reasoning နည်းသည့်အတွက် complex tasks တွေထက် simple retrieval တို့အတွက် သင့်တင့်ပါတယ်။ - Verbosity
verbosity parameter အသစ်သည် တုံ့ပြန်စာသား အလျားကို ထိန်းချုပ်ပေးပြီး (low, medium, high) ရွေးချယ်နိုင်ပါတယ်။ ဥပမာ "5 paragraph essay ရေးပါ" ဆိုပါက အမြဲ 5 paragraph ထွက်ပေမယ့် paragraph အရှည်တို/ရှည်က verbosity ပေါ်မူတည်ပါသည်။ - Preamble messages before tool calls
Tool calls များ မတိုင်မီ အဆင့်ဆင့် အစီအစဉ်/တိုးတက်မှုကို ဖော်ပြပေးပြီး၊ ကြာရှည်တဲ့ tasks တွေမှာ ပိုပြီး ထင်ရှားမြင်သာစေပါတယ်။ - Custom tools
GPT-5 သည် JSON မလိုအပ်ဘဲ plaintext ဖြင့် tool calls လုပ်နိုင်တဲ့ tool အမျိုးအစားအသစ်ကို ထောက်ပံ့ထားပြီး၊ regex သို့မဟုတ် grammar constraints ဖြင့် input ကို ထိန်းချုပ်နိုင်ပါတယ်။ ဒီအတွက်ကြောင့် lengthy code/report များထဲမှာ အမှားနည်းစေပြီး SWE-bench Verified ပေါ်မှာလည်း JSON tools နဲ့ စွမ်းဆောင်ရည် အတူတူရှိပါတယ်။
Safety
GPT-5 သည် ပိုမို လုံခြုံပြီး ယုံကြည်စိတ်ချရပါသည်။ Hallucination အရေအတွက် လျော့နည်းစေသည့်အပြင်၊ မိမိ၏ စွမ်းဆောင်နိုင်စွမ်းများကို တိကျစွာ ဖော်ပြပေးနိုင်ပါတယ်။ အမြဲတမ်း သုံးစွဲသူအတွက် အကောင်းဆုံး အဖြေကို ပေးနိုင်ရန် ကြိုးစားထားပြီး၊ လုံခြုံရေး ညွှန်ကြားချက်များကို လိုက်နာထားပါတယ်။
Availability & Pricing (GPT-5 for Developers)
GPT-5 ကို အခုအချိန်မှာ အမျိုးအစားသုံးမျိုးနဲ့ အသုံးပြုနိုင်ပါသည် –
- gpt-5
- $1.25 (1M input tokens )
- $10 (1M output tokens )
- gpt-5-mini
- $0.25 (1M input tokens )
- $2 (1M output tokens )
- gpt-5-nano
- $0.05 (1M input tokens )
- $0.40 (1M output tokens )
API အားလုံးတွင် – reasoning_effort, verbosity, custom tools, parallel tool calling, built-in tools (web search, file search, image generation စသည်) ထောက်ပံ့ထားပြီး၊ prompt caching နဲ့ Batch API ကဲ့သို့သော cost-saving feature များပါ ပါဝင်ပါတယ်။
Non-reasoning ChatGPT ဗားရှင်းကိုလည်း gpt-5-chat-latest အဖြစ် GPT-5 ဈေးနှုန်းနဲ့ အသုံးပြုနိုင်ပါတယ်။
နောက်ထပ် Microsoft 365 Copilot, GitHub Copilot, Azure AI Foundry စတဲ့ Microsoft product များထဲမှာပါ GPT-5 ကို မိတ်ဆက်ထားပါသည်။
Check out the GPT-5 for developers , documentation(opens in a new window), pricing details(opens in a new window), and prompting guide(opens in a new window) to get started.
Microsoft 365 နဲ့ အခြားသော Products များအကြောင်းစိတ်ဝင်စားပါက သို့မဟုတ် ပိုမို သိရှိလိုပါက Thetys Myanmar သို့ ဆက်သွယ်ပြီး အသေးစိတ် မေးမြန်းဆွေးနွေးနိုင်ပါတယ်ခင်ဗျ။
reference website : Fusion Solution, Fusion Solution Vietnam
Related Articles
- Jarviz: လွယ်ကူပြီး လုံခြုံမှုမြင့်မားသော Check in ဝင်ရောက်မှု စနစ်
- GPT 5 — ၂၀၂၅ ခုနှစ်အတွင်း OpenAI မှ ထုတ်လုပ်သော အကောင်းဆုံးနဲ့ အမြန်ဆုံး AI Model
- Microsoft 365 tools များ အသုံးပြုပြီး Creativity မြင့်တင်ခြင်း
- AI Prompt ဆိုတာဘာလဲ နှင့် ဘယ်လိုအလုပ်လုပ်သလဲ?
- Power BI အသုံးပြုခြင်းရဲ့ Benefits များ
- GitHub Copilot Plans များအကြောင်း